Kirkpatrick S
Measurement Error in
Dietary Assessment
3rd Edition November 2025
Abstract
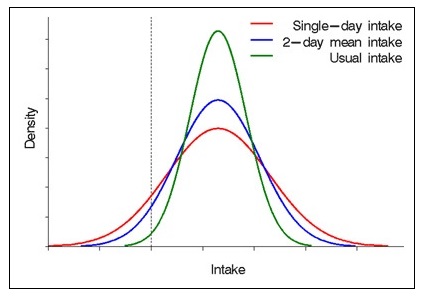
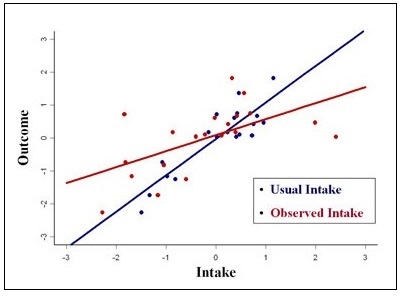
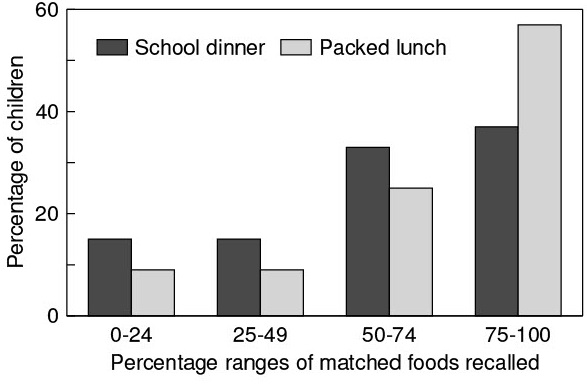
Data on food consumption are typically collected using self-report methods. The resulting data are affected by measurement errors that can have serious consequences for study findings and interpretation. measurement error refers to the difference between true and observed intake and may be random or systematic. Errors arise due to the interaction of the participant with the assessment method and can also be generateded by interviewers and coders, as well as by limitations in food composition databases. Accordingly, the type and extent of the errors vary with the method used and how it is implemented, the target population of interest, and the nutrients and foods investigated. Both unaddressed random and systematic measurement error can introduce substantial bias into results. Pertinent to surveillance and monitoring, measurement error can lead to erroneous inferences about the proportions of a population with inadequate or excessive intakes relative to nutrient requirement estimates and food group recommendations. In epidemiologic research, measurement error distorts observed associations between diet and disease, as well as reducing statistical power to detect such associations. In intervention research, measurement error can mask the effects of the intervention, particularly if the error is differential between intervention and control groups. Strategies to minimize and/or mitigate error are therefore fundamental to research making use of dietary intake data and should be considered early in study design through to reporting results and implications. CITE AS: Kirkpatrick S, Principles of Nutritional Assessment: measurement Error in Dietary Assessment https://nutritionalassessment.org/errors/Email: skirkpat@uwaterloo.ca
Licensed under CC-BY-4.0
( PDF ) ( epub )